機器學習模型的建立和部署,和一般的軟體專案有什麼不同嗎?為什麼需要特別拉出來討論呢?Google 在 2015 年發表的〈Hidden Technical Debt in Machine Learning Systems〉中介紹許多機器學習專案會遇到的技術債問題,而這些是傳統軟體開發所缺乏的。
大家應該很常看到這張圖,說明現實社會中的一個機器學習專案中,其實 ML code 只佔非常小的一部分,多數時間跟心力都耗費在如何蒐集和處理數據、系統的 infra 架構、如何監控等等。
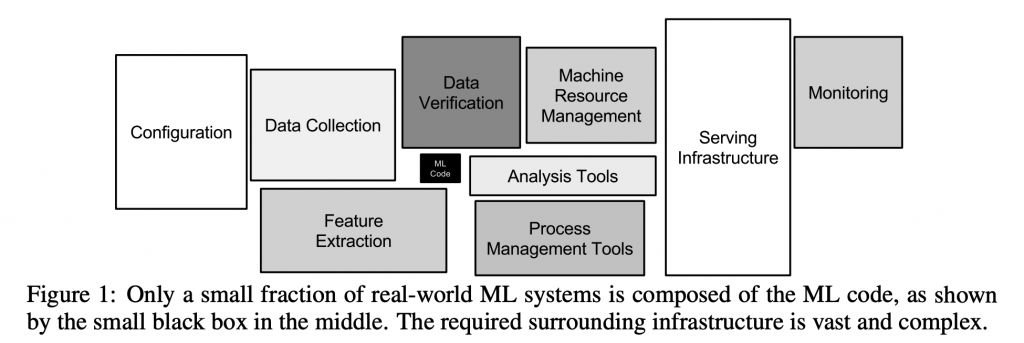
接下來,讓我們來看看 ML 專案很容易遇到的一些技術債問題吧!
傳統軟體工程強調透過封裝和模組化設計來建立清晰的抽象邊界,以便於維護和修改程式碼。然而,一個機器學習模型會將各種特徵混在一起,產生複雜的交互影響,任何微小的變動都可能影響整個系統的行為,導致難以獨立改進模型的任一部分,Google 稱之為 CACE 原則(Changing Anything Changes Everything)——改變任何東西都會改變一切。
舉例來說,當一個模型使用到 x1、x2、⋯⋯、xn 等多個特徵時,若改變 x1 的資料分布,所有其他特徵的權重或使用方式可能都會跟著改變,更遑論如果我們增減一個特徵。除了輸入模型的資料特徵以外,模型的超參數(hyper-parameters)、模型和資料的挑選方式等等也都符合這個原則。
機器學習系統通常具有複雜的數據依賴關係,例如特徵工程(feature engineering)、數據預處理(data preprocessing)、模型訓練等環節都依賴不同的數據和處理流程。
數據依賴有兩種類型:
不穩定的資料依賴(Unstable Data Dependencies):如果 ML 模型依賴的輸入資料隨著時間而變化,會導致系統難以維護,甚至可能出現錯誤。資料變化可能是隱性(implicit)的,例如輸入特徵是另一個模型的輸出,而此模型發生變化時,或是自然語言處理上常用的 tokenizer,在處理 tokens 時發生變化。
未充分利用的資料依賴(Underutilized Data Dependencies):如果模型中包含對預測結果沒有幫助的輸入特徵,會增加系統的複雜性和維護成本,例如以下幾種特徵:
如果沒有妥善管理,例如版本控制或工作流程的管理工具等,會導致系統變得脆弱,難以維護和更新。因此,與程式碼一樣,資料和模型也應該納入版本控制,不僅可以幫助追蹤資料和模型的變化,並更容易地回復到之前的版本。
我們在之後會介紹 Netflix 和 Spotify 是如何建立資料和工作流程管理平台,來管理他們龐大又複雜的數據和處理流程。
機器學習系統還有一些常見的模式,但是這些是不良的設計方式,應該要極力避免,否則會讓系統變得複雜、不易維護或擴展。
隨著時間推移,ML 系統中可能會累積無用的程式碼和特徵,因此,資料團隊需要定期審查和刪除無用的程式碼和特徵,降低系統的複雜性和維護成本。
在認識到 ML 專案和一般軟體專案的不同,以及他們可能造成的技術債問題之後,我們會在明天介紹 Andrew Ng 在認為完整機器學習專案會包含的五個步驟。接著,在之後的文章中介紹各大科技公司的實際案例,學習他們如何解決這些問題的!
參考資料
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!

